越來越多(duō)地研究提出了醫(yī)療人工(gōng)智能(néng)(AI)算法,用(yòng)于評估和護理(lǐ)患者。但尚無現成的最佳實踐來評估商(shāng)業可(kě)用(yòng)算法,以确保其可(kě)靠性和安(ān)全性。通往安(ān)全和強大的臨床人工(gōng)智能(néng)的道路需要解決重要的監管問題。醫(yī)療設備的性能(néng)是否可(kě)以推廣到所有(yǒu)預期人群?人工(gōng)智能(néng)普遍面臨的缺點(對訓練數據的過度拟合、數據轉移的脆弱性和對未充分(fēn)代表的患者亞組的偏見)是否得到充分(fēn)量化和解決?
2021年4月05日由斯坦福大學(xué)James Zou研究組在《Nature Medicine》雜志(zhì)上發表了一篇名(míng)為(wèi)“How medical AI devices are evaluated: limitations and recommendations from an analysis of FDA approvals”的評論文(wén)章。在本研究中(zhōng)創建了一個帶批注的FDA批準的醫(yī)療AI設備數據庫,并系統分(fēn)析了這些設備在批準前的評估方式。對氣胸分(fēn)類裝(zhuāng)置進行了案例研究,發現僅在單個站點上評估深度學(xué)習模型(通常這樣做)就可(kě)以掩蓋模型的弱點,并導緻跨站點的性能(néng)下降。

越來越多(duō)地提出了醫(yī)療人工(gōng)智能(néng)(AI)算法,用(yòng)于評估和護理(lǐ)患者。在美國(guó),美國(guó)食品藥品監督管理(lǐ)局(FDA)負責批準商(shāng)業銷售的醫(yī)療AI設備。FDA以摘要文(wén)件的形式發布已批準設備的公(gōng)開可(kě)用(yòng)信息,該摘要文(wén)件通常包含有(yǒu)關設備描述,使用(yòng)說明和設備評估研究的性能(néng)數據的信息。FDA最近呼籲提高測試數據質(zhì)量,提高與用(yòng)戶之間的信任和透明度,監控算法性能(néng)和對預期人群的偏見,并讓臨床醫(yī)生參與測試,為(wèi)了了解這些問題在實踐中(zhōng)得到解決的程度,創建了一個帶批注的FDA批準的醫(yī)療AI設備數據庫,并系統分(fēn)析了這些設備在批準前的評估方式。
我們彙總了2015年1月至2020年12月期間獲得FDA批準的所有(yǒu)醫(yī)療人工(gōng)智能(néng)設備,提取了以下關于如何評估算法的信息:參與評估研究的患者人數;評估中(zhōng)使用(yòng)的場地數量;測試數據是在設備部署時同時收集和評估(前瞻性)還是在設備部署前收集測試集(回顧性);以及是否報告了按疾病亞型或跨人口亞組的分(fēn)層表現。此外,根據FDA提案4的指導方針将每個設備的風險等級從1到4(1和2表示低風險;3和4表示高風險)。總共,彙編了130個符合我們審查标準的經批準的設備(如圖1)。
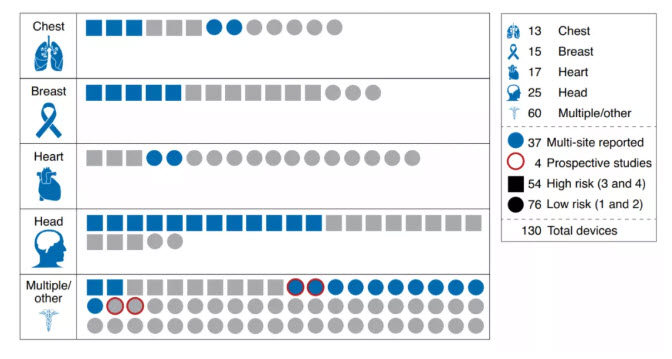
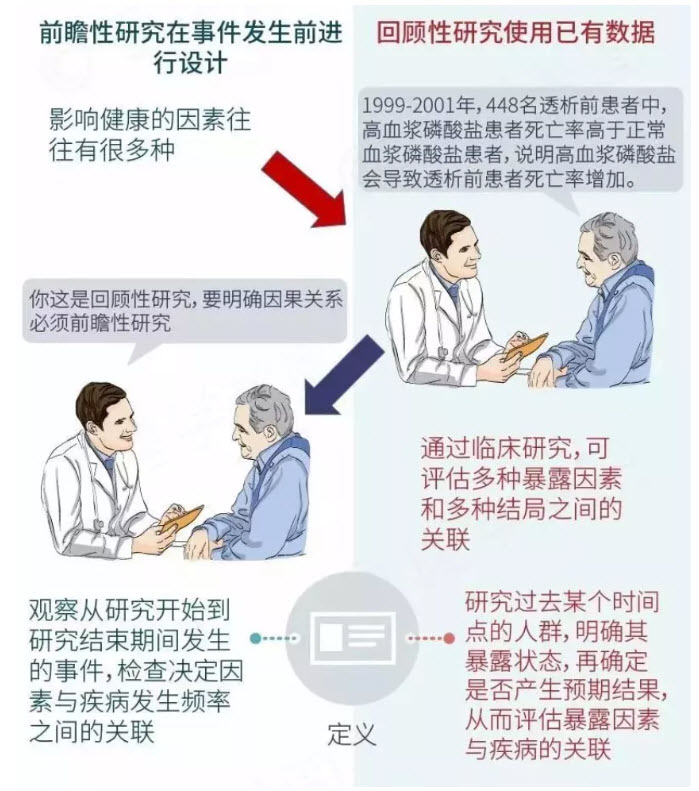
根據FDA的總結,幾乎所有(yǒu)的人工(gōng)智能(néng)設備(130個中(zhōng)的126個)在提交時都隻進行了回顧性研究。未對54種高危裝(zhuāng)置進行前瞻性研究評估。對于大多(duō)數設備,回顧性研究的測試數據是在評估前從臨床站點收集的,測量的終點不涉及臨床醫(yī)生在人工(gōng)智能(néng)和不人工(gōng)智能(néng)情況下的表現的并排比較。需要更多(duō)的前瞻性研究來全面描述人工(gōng)智能(néng)決策工(gōng)具(jù)對臨床實踐的影響,這一點很(hěn)重要,因為(wèi)人機交互可(kě)能(néng)會從本質(zhì)上偏離模型s的預期用(yòng)途(如圖2)。
且通常不報告評估地點和樣品的數量,在分(fēn)析的130台設備中(zhōng),93台設備沒有(yǒu)公(gōng)開報道多(duō)場所評估作(zuò)為(wèi)評估研究的一部分(fēn)。報告的41台設備中(zhōng),僅1個站點評價4台設備,僅2個站點評價8台設備。這表明,相當一部分(fēn)被批準的設備可(kě)能(néng)隻在少數幾個地點進行了評估,而這些地點往往具(jù)有(yǒu)有(yǒu)限的地理(lǐ)多(duō)樣性。多(duō)部位評估對于理(lǐ)解算法的偏倚和可(kě)靠性很(hěn)重要,可(kě)以幫助計算所使用(yòng)的設備、技(jì )術标準、圖像存儲格式、人口構成和疾病患病率的變化。
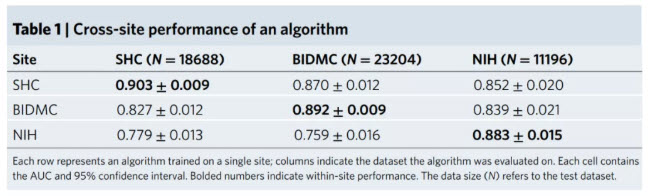
了解一個模型的性能(néng)如何可(kě)以推廣到廣泛和多(duō)樣化的人群是至關重要的,研究者探索了AI模型如何在代表不同人群的多(duō)個臨床站點的患者身上進行評估。已目前批準的4種用(yòng)于氣胸檢測的AI設備為(wèi)例,使用(yòng)三個來自不同地區(qū)醫(yī)院患者的數據集(SHC,BIDMC,NIH),在三個區(qū)域的患者數據上訓練了三個獨立的深度學(xué)習模型,然後評估來自其他(tā)兩個區(qū)域的測試集上的模型。每個模型以胸透圖像作(zuò)為(wèi)輸入,并對氣胸進行二元預測。結果總結顯示(如圖3),雖然位點内測試的AUC仍然很(hěn)高(平均0.893),但性能(néng)顯著下降了平均0.072 AUC,在其他(tā)兩個位點評估時達到0.124 AUC。一些性能(néng)變化可(kě)能(néng)是由于跨位點的患者人口統計差異。
總而言之,本文(wén)通過總結目前FDA批準上市AI醫(yī)療設備的評估方式,發現了目前評估上市所存在的問題,對未來評估人工(gōng)智能(néng)設備在多(duō)個臨床站點的性能(néng)對于确保算法在代表性人群中(zhōng)表現良好很(hěn)重要。鼓勵前瞻性研究與标準護理(lǐ)相比較,可(kě)以降低有(yǒu)害過度拟合的風險,并更準确地捕捉真實的臨床結果。人工(gōng)智能(néng)設備的上市後監測也需要理(lǐ)解和測量在前瞻性、多(duō)中(zhōng)心試驗中(zhōng)未檢測到的非預期結果和偏差。
----------THE END----------
免責聲明:本文(wén)系轉載分(fēn)享,文(wén)章觀點、内容、圖片及版權歸原作(zuò)者所有(yǒu),如涉及侵權請聯系删除!
Copyright © 2017 京ICP證000000号